





At its I/O event this week, Google gave us our most comprehensive preview so far of how it intends to reshape its search engine in response to the wave of hype surrounding generative AI and chatbots. What they demonstrated was not only a very different vision for how we get information online, but also an ambitious and worrying push to further move the open web onto the company’s platform.
The philosophy behind Google’s search engine was previously associated with its “10 blue links.” When you put a query in its search bar, you’d get ten results — along with some ads — based on the algorithm that allowed it to dominate online search in the early days of the web. It’s been slowly moving away from that approach for years, but the I/O announcements signal a fundamental shift in its approach.
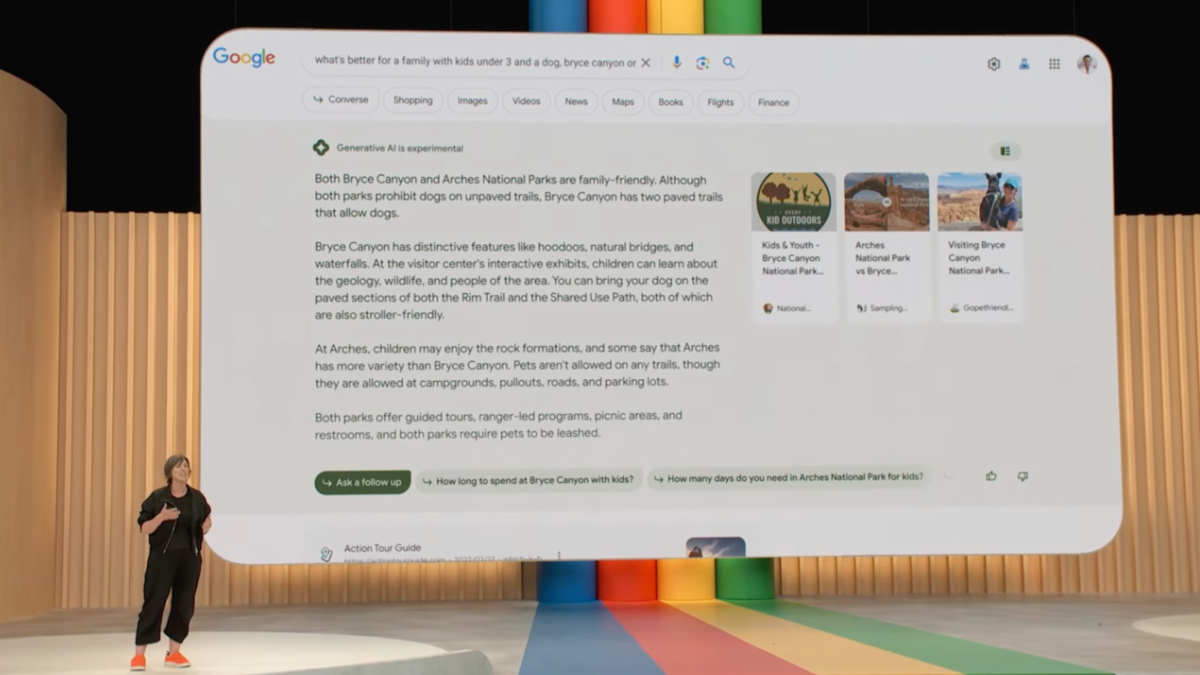
During the demo, the company showed off how it envisions search will work in the future: you’ll enter your prompt as usual, then the blue links will appear, but within a few seconds the Search Generative Experience will generate an answer in a section on a lightly colored background that will expand to push the blue links off the screen entirely. That answer will be generated by a large language model trained on the open web itself, and while it will cite some websites you can click on for further information, the goal is very clear: to ensure you spend more time getting answers from Google, and less from all the sources across the web that it’s pulling from to generate those answers.
In February, I argued that the narrative around ChatGPT and Microsoft challenging Google was all wrong. Sure, Bing might take a small chunk out of Google’s search dominance, but ultimately the benefit to Google was much greater: it got an excuse to push much harder on AI integration and to further exert its power over the web for its own benefit. The announcements at I/O show us that’s exactly what it’s doing.
Google’s previous efforts
Since its early days, Google has not only relied on the open web, but also had a lot of influence over any website owner wanting traffic and to make money. There would be no search without a web of disconnected websites; that was the whole point of Google: to sort through them and show you the websites that best reflected what you were looking for. But as its dominance was cemented, its policy changes and algorithmic tweaks had to be closely watched by webmasters.
A whole industry sprang up around search engine optimization as websites sought to improve their Google rankings and benefit from the traffic that followed. Today, we can see the effects of that: the results for many of people’s queries are no longer filled with helpful links that answer people’s questions, but websites that are stuffed with useless information yet perfectly optimized to rise to the top. That’s exactly why Microsoft’s partnership with OpenAI to integrate ChatGPT into Bing caused some real questions about whether Google could keep its crown. Many people even append their Google queries with “site:reddit.com” if they really want to get some useful information because the company has let its search experience degrade so dramatically in recent years.
But that’s not the only way it’s tried to control the open web. Beyond the fact its trackers for analytics and ads are virtually everywhere, in 2015 it also launched Accelerated Mobile Pages, or AMP, which it said was about improving the experience of reading news on mobile devices as they were on the cusp of becoming the primary means of using the search engine. But a recent deep dive in The Verge explains that wasn’t the true motivation.
As Google saw competitors like Facebook and Apple making news apps, AMP was a way to speed up the mobile web, but also shift a lot of power over how it worked into Google’s hands. AMP webpages prioritized Google’s ad trackers, which the US Justice Department argued in a January 2023 lawsuit was “an effort to push parts of the open web into a Google-controlled walled garden, one where Google could dictate more directly how digital advertising space could be sold.” But since it gave publishers access to the Top Stories carousel, they had little choice but to participate.
Ultimately, AMP failed. Many publishers have abandoned it in recent years as Google itself failed to deliver on the vision it promised. It has still pursued other means of using the open web to its benefit though. Even before the ongoing integration of chatbots, Google has been scraping information off the web for years and displaying it on the search engine in a way that’s been annoying a lot of other companies and website owners.
For example, it has its flight comparison service, and the shopping tab that won it a $2.7 billion fine from the European Union for anticompetitive practices. But there’s also the featured snippets and knowledge panels that pull information about certain topics from other websites that makes many users less likely to continue through to the website actually responsible for collecting and publishing the information in the first place. Those features have been making publishers angry for years, but generative AI will make that far worse.
How AI enhances corporate power
AI boosters love to talk about all the supposed benefits we’ll get from widespread adoption of chatbots and other generative AI tools. They’ll apparently become our doctors and teachers, not to mention virtual personal assistants. But all those benefits are theoretical, and if we know anything about Silicon Valley, it’s that they have a bad record of following through on the positive aspects of their visions, while underestimating — or distracting us from — the many drawbacks.
But Google’s plan for the future of search shows us there are going to be very clear tradeoffs if we embrace the vision advocated by these companies. After building its business on the open web, Google has now scraped it onto its servers and will serve up paragraphs plagiarized from the very websites that used to depend on it for traffic. In the process, it will make it unnecessary for many users to continue beyond Google to those other websites, but will allow Google to sell more ads against the content it’s generated based on other people’s work.
Google’s efforts show how power is really being wielded behind the curtain of AI hype. We need to be aware of how companies are using this moment to further centralize power and increase their control over our experience of the web and everything we’ve ever contributed to it. The threat here isn’t sci-fi fantasies of intelligent computers that could exist in the distant future; it’s what companies are doing today that will have serious ramifications for people’s lives — and in many cases already is.
Generative AI depends on large language models trained on vast quantities of data taken from the open web, all operating with centralized computing power that only a few companies around the world have the capability to control. If this is the future of digital technology, it also requires the Googles and Microsofts of the world to maintain their positions far into the future. But it also means publishers will continue to be starved of revenue for journalism and artists will see their livelihoods threatened, with serious ramifications for all us as we continue toward our march toward an increasingly anti-human world in service of the power and profits of the tech industry.
Member discussion